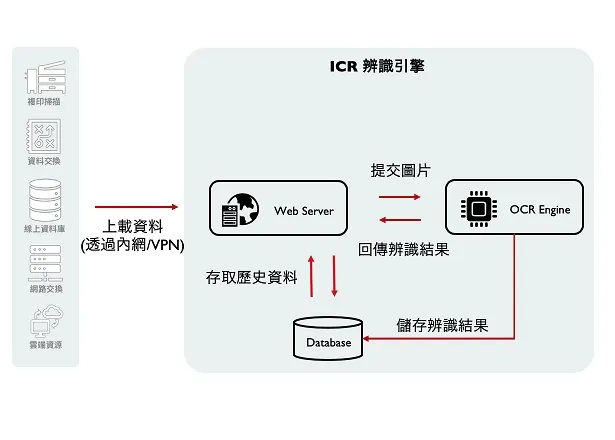
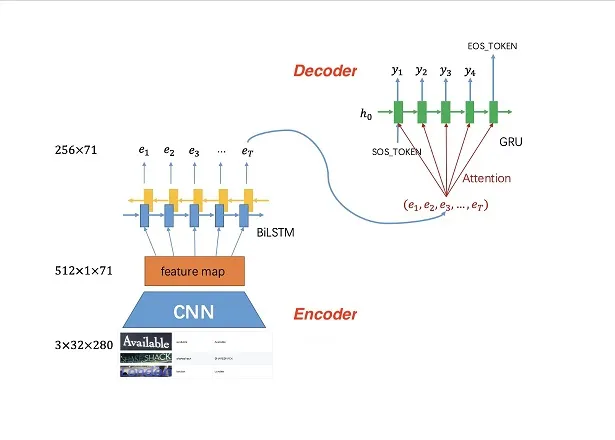
我們的「智慧字元辨識技術」融合了傳統光學字元辨識(OCR)和先進大型語言模型(LLM),不僅能在數秒內快速辨識圖片或文檔中的文字,還能深入理解文本內容與語意脈絡。系統支援 JPG、PNG、PDF、TIFF 等常見圖檔與文件格式,無論是掃描文件、手機拍攝的照片,或是多頁 PDF 報告,都能高效處理並輸出結構化文字資料。
不同於傳統 OCR 僅能逐字辨識,我們的系統透過 LLM 進一步理解文件語意,可自動校正辨識錯誤、補全缺漏文字,並根據上下文判斷專業術語。您只需上傳圖片或文檔,系統即自動完成辨識、語意分析並輸出結果,大幅節省人工輸入與校對時間。無論是金融業的合約審查、製造業的品質檢測,或是媒體產業的內容數位化,OCR + LLM 都能為您的工作流程帶來顯著效率提升。
針對企業日常大量的合約、發票、報表等紙本文件,系統可快速批次辨識並轉為結構化數位資料。結合 LLM 語意理解,自動擷取關鍵欄位(如金額、日期、簽署方),並進行合規性初步比對,大幅縮短人工審閱時間,降低人為疏漏風險。
即時擷取電視新聞跑馬燈、節目字幕、廣告文字,以及雜誌、報紙的圖文內容,自動轉為可搜尋的文字資料。搭配關鍵字比對引擎,快速掌握品牌曝光狀況、競品動態與輿論風向,是公關與行銷團隊進行媒體監測的利器。
自動辨識產線機台儀表板、量測設備顯示器上的數值與文字,即時轉換為數位數據並回傳至 MES 或 ERP 系統。取代人工抄錄流程,不僅提升數據即時性與正確性,更可結合異常值偵測,實現產線品質自動監控與預警。
精準辨識複雜表格結構與手寫表單內容,自動保留行列關係並輸出為 Excel 或 CSV 格式。無論是財務報表、出貨單、醫療紀錄表或問卷調查,系統皆能正確解析合併儲存格、多層表頭等複雜版面,省去繁瑣的人工重建工作。
支援繁體中文、簡體中文、英文、日文等多種語言辨識,並能處理中英混排、中日混排等混合語言文件。針對中文特有的繁簡變體、異體字,以及日文漢字與假名混用的情境,系統皆具備高度辨識準確率,適用於跨國企業與多語言文件處理需求。
突破傳統 OCR 僅能逐字辨識的限制,結合大型語言模型深度理解文件語意。系統可自動摘要長篇文件、回答文件內容相關問題、標記關鍵資訊,並偵測文件中的矛盾或異常之處。讓文件辨識從「看得到文字」升級為「讀得懂內容」。
雲端與地端部署
支援 JPG / PNG / PDF / TIFF
繁中 / 簡中 / 英 / 日多語言
OCR + LLM 語意辨識