打造企業AI大腦:如何利用微調、RAG與提示詞工程強化企業核心技術

自從 ChpatGPT 等AI 技術問世,各家公司都在盼望能藉 AI 提升工作效率,簡化繁瑣流程,進而降低成本。但ChatGPT 固然頭腦靈光,以下幾個疑慮還是讓不少企業對於把它納入日常運作有所保留:
- 專業性方面:ChatGPT雖然看似無所不知,但卻無法接觸到公司內部的資料,這導致它無法與現有工作流程完美對接。
- 隱私性方面:像三星這類公司用ChatGPT來解決工作上的難題,結果卻發現公司機密洩露的問題。
- 整合性方面:如果AI無法與公司既有的流程或系統銜接,那麼對於流程自動化的幫助就有限。
為此,Llama2 的誕生似乎未企業點亮了一盞明燈,如果能在企業內部安裝 Llama2,似乎就可以解決以上所有問題。但問題是,Llama2雖然在英文問答上表現出色,對於中文的處理卻因為訓練資料的限制而顯得力不從心。此時,不少公司或公部門單位(例如 Taide 計畫)即開始思索能不能夠用中文資料對Llama2 進行微調(Fine-Tuning), 讓它更了解中文和中文相關知識。
然而,微調模型並非想像中那麼簡單。除了工程師需要有微調的知識與技術外,微調需要相當的計算力。就現況而言,不是每家公司都如美國科技巨頭FANNG,都可以輕鬆購置一堆GPU 跟聘用人工智慧博士搭建企業專屬的模型。事實上,除了微調之外,還有其他幾種企業可以考慮的方案。
目前企業可以考慮的AI導入方式包括提示詞工程、模型微調和資料檢索增強生成(RAG),或者是將這些方法綜合運用。至於選擇哪一種方式,可以參考以下的標準:
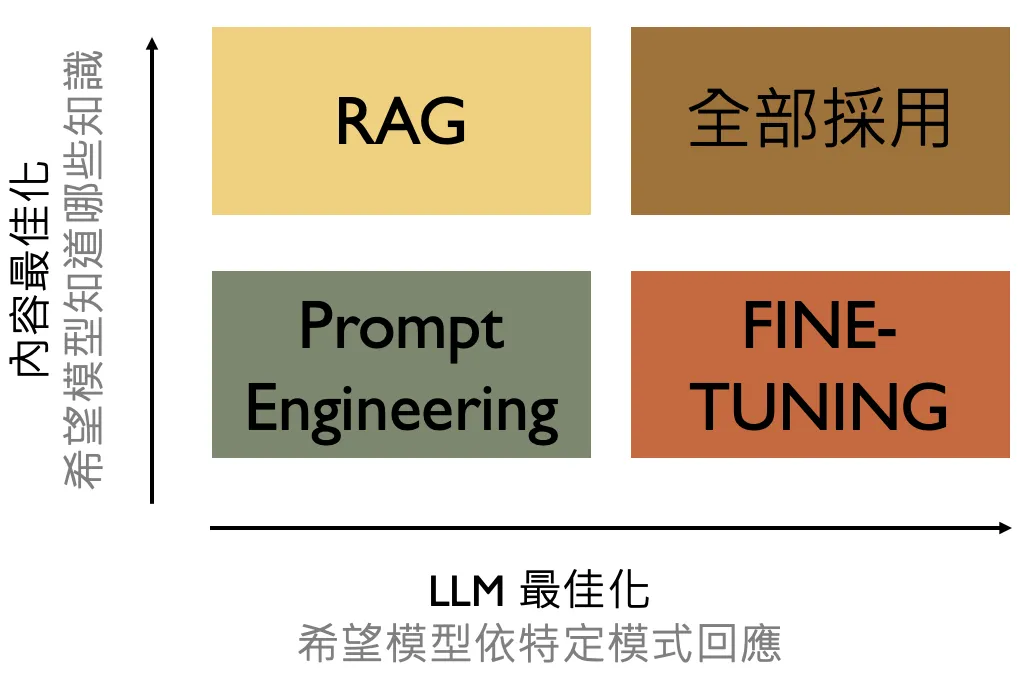
- 模型微調(Fine-Tuning): 如果你希望模型產生符合特定格式的結果(比如輸入文字後產生SQL),可以考慮採用模型微調。
- 資料檢索增強生成 (RAG): 如果希望能夠為ChatGPT 加掛企業知識庫,可以採取 RAG 模式。
- 提示詞工程(Prompt Engineering): 通過更有效的問題提出方式,例如給予大型語言模型多個範例,其實就能夠改善模型的回答品質。
以下針對每個導入方法做詳細介紹:
1. 模型微調(Fine-Tuning)
對Llama2模型進行微調對許多企業來說是個不錯的選擇。這個過程主要是調整和優化預先訓練好的模型,讓它更貼合特定的應用或需求。比如說,經過微調,Llama2就能根據特定的指令產生SQL語句,或者產出更符合台灣用語的回答。
但微調的成本相當高。以Taiwan-LLM的開發為例,所需硬體資源包括8張A100 80G GPU運行兩周及12小時的指令微調。A100的售價大約在50萬元左右,8張就要400萬元。當然,也可以選擇租用雲端服務,像是GCP、Azure、AWS等,但微調是個長期試錯的過程,還需要AI工程師精通LoRA、QLoRA、DPO、RLHF等專業技巧,並找到高品質的資料集。這種工作通常只有大公司或政府機構才能承擔。而且就算條件都符合,有時候經過微調的大型語言模型,像是Taiwan LLM在ikala公布的TMMLU資料集中,表現也只能算是末段班,更別說常常微調完了還不如原來的模型呢。
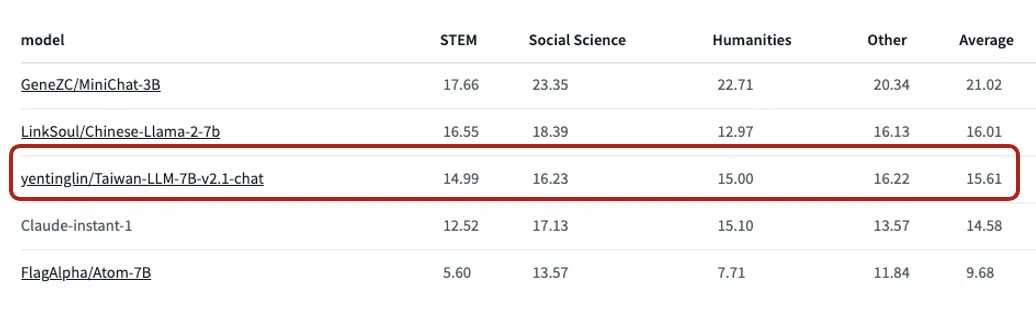
但如果你想要用現成的私有模型,其實市場上也有不少選擇。以ikala公布的評測集和C-Eval來看,目前阿里巴巴的通義千問就是個不錯的選擇,它在邏輯和中文處理能力上不遜色於GPT 3.5,值得企業內部考慮採用。但對公部門來說,可能就不太適合。另外,如果考慮英文模型,法國新創公司Mistral AI推出的Mistral-8x7b就是佼佼者。
至於台灣繁體中文原生的模型,目前市面上還沒有一個特別出色的選項。
模型微調的優點與缺點:
優點:能夠精確滿足特定使用者需求,提升模型在特定領域或語言上的效能。
缺點:成本高,需要大量硬體資源和時間,並且可能會降低模型的通用性。
2. 資料檢索增強生成(Retrieval Augmented Generation, RAG)
RAG結合了檢索(Retrieval)和生成(Generation)兩種技術,利用語義向量技術深入分析既有知識庫或資料庫,為每篇文章創建語義向量(Embedding),並將之整合進向量資料庫(Embedding Database)。當使用者提問時,系統會先找到與問題最相關的文件,作為回答生成的上下文脈絡,這方式能在不需更動原模型的情況下,提供更加精確的答案。
目前,最簡單部署RAG的途徑是使用ChatGPT Plus的GPTs功能,或者利用OpenAI的Assistant API。但若企業想要自行建立專屬的向量資料庫,就得依靠Chroma、Supabase或Qdrant等資料庫解決方案,配合Langchain或LLamaIndex等開源框架,來打造適合自家的RAG應用。
不過,僅用RAG並不能完全解決隱私問題。因為當文件作為回答生成的上下文時,敏感資訊可能會不慎外洩。這時候,結合使用如Mistral-8x7b或通義千問(QWEN)這樣的大型語言模型,可以作為一個安全的生成引擎。但如果對開源模型存有疑慮,那麼可以考慮使用Azure的OpenAI API。雖然將資料上傳到雲端可能有一定風險,但在微軟的品牌加持下,這風險可望降到較低程度。
至於單獨使用RAG的效能表現如何呢?根據微軟的研究,單純使用RAG在許多評測項目勝過了RAG + 微調模型的組合。因此,若企業的目標是低成本實現AI整合,RAG無疑是個成本效益高的選擇。
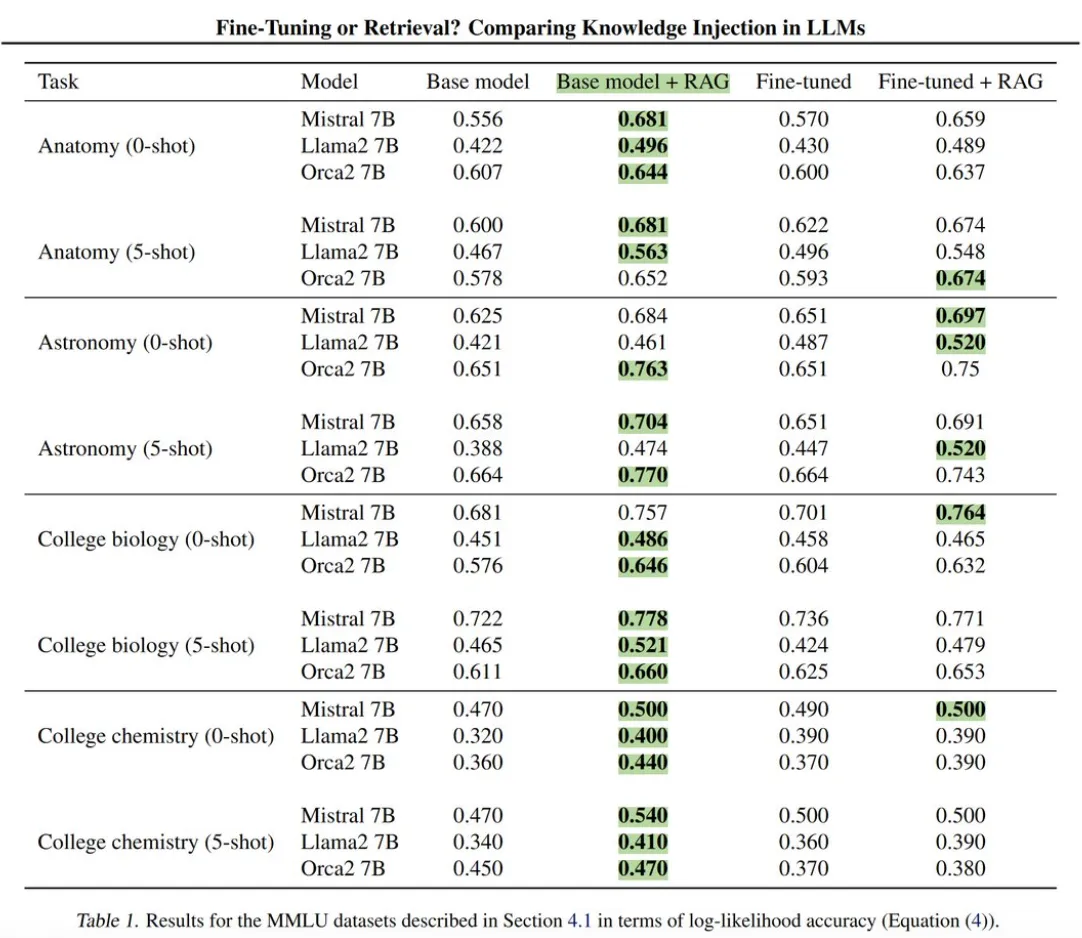
資料檢索增強生成的優點與缺點
優點:RAG能夠利用豐富的資料庫來提供更精準、更全面的回答,同時避免對原始模型做大幅度調整。
缺點:RAG在處理含有敏感資訊的文件時對隱私保護有限,且其效能高度依賴於資料檢索品質。
3. 提示詞工程(Prompt Engineering)
提示詞工程(Prompt Engineering)強調如何通過更有效的問題提出方式來改善模型的回答品質。這種方法不需要額外的硬體資源或專業知識,只需要根據具體情況調整問題的提出方式。
常有人問,既然人工智慧這麼聰明,為什麼還需要學會怎麼用提示詞呢?
其實,ChatGPT的智慧程度跟它的訓練資料有著密切關係。比方說,如果想要用繁體中文獲得回答,用“正體中文”來提問通常會得到更精準的回應。這是因為在訓練過程中,模型對“正體中文”這個詞彙有更深刻的理解。
此外,運用few-shot prompting、Chain of Thoughts等技巧可以進一步提升ChatGPT的回答精確度。最近微軟的研究顯示,恰當的提示詞應用,甚至可以在不做任何微調的情況下,提高ChatGPT在特定領域(例如醫學問答)的表現,超越Google 開發的醫學問答模型Med-PaLM。
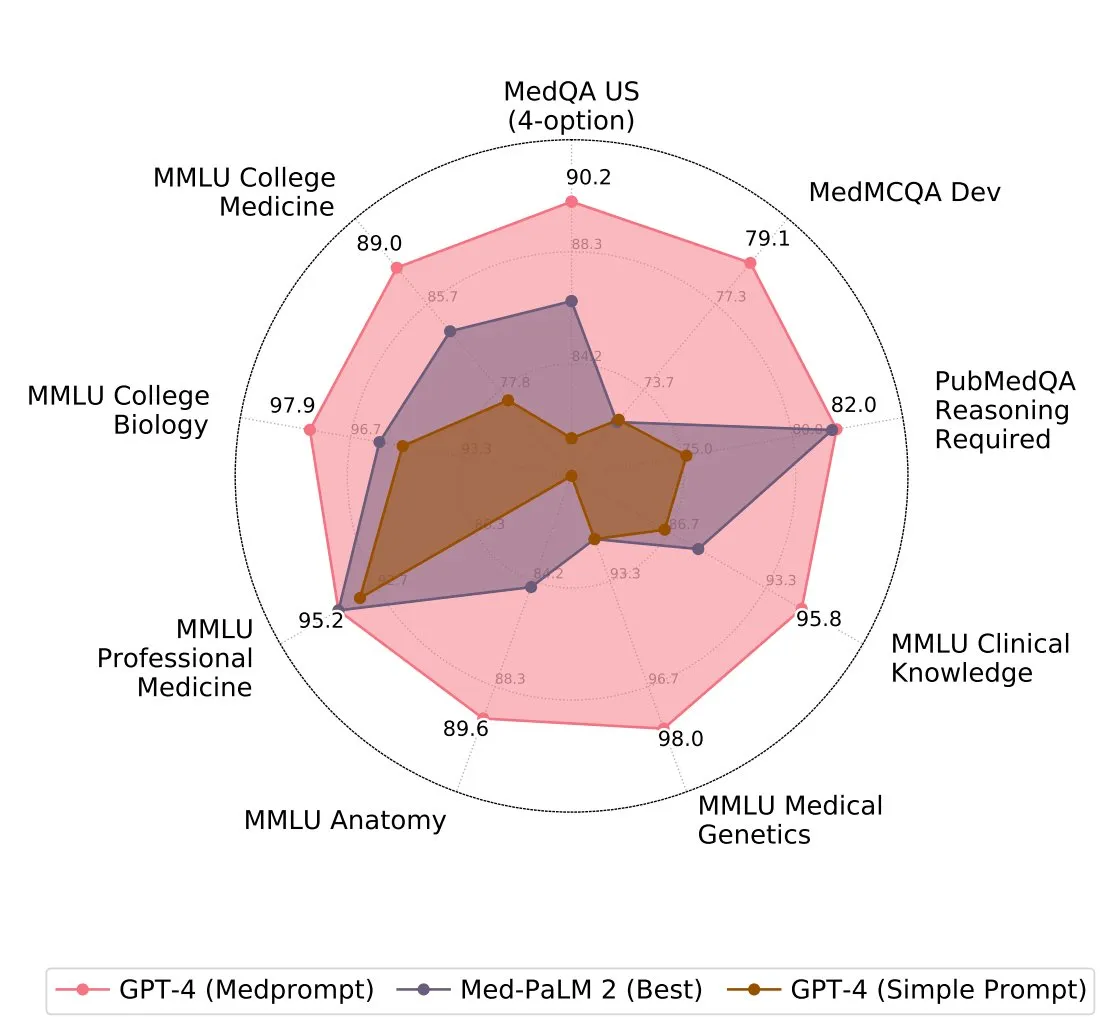
提示詞工程(Prompt Engineering)的優點與缺點
優點:提示詞工程無需額外硬體或大量數據,能快速實施並顯著提升AI回答品質。
缺點:設計有效的提示詞對非專業使用者來說可能有學習曲線,且在複雜場景中效果有限,需要不斷更新調整以適應變化。
全部採用
就像流行的網路用語「小孩子才做選擇,我全都要」一樣,企業可以運用模型微調(Fine-Tuning)、資料檢索增強生成(RAG)及提示詞工程(Prompt Engineering)等多種手法,打造出一個功能全面且靈活的AI系統。這樣的系統不僅能處理特殊領域的複雜問題,也能應對各種一般性問題。微調讓解決方案更加個性化,RAG則提升了問題處理的準確度和相關性,而提示詞工程則增強了系統的易用性和使用者體驗。這種全方位策略不僅提升了企業的營運效率,也讓AI技術的實用性和可用性大大增強。但全面採用也是對公司財力與人力的一大考驗,企業需權衡相關成本與投資回報率後再做決策。
總結
隨著AI技術不斷進步,企業可望更廣泛地將這些技術融入內部運作,進而降低成本、提升效率。然而,在運用這些技術時,找到保護隱私與控制成本之間的平衡點是未來導入的重要關鍵。
目前,大數軟體公司正在積極探索將提示詞工程、RAG和本地端大型語言模型結合的策略,以低成本、高效率的方式為客戶提供智慧型輿情服務和知識管理服務。對於有意在企業內部應用RAG的企業,我們非常歡迎你們與我們聯繫,一起探討合作的可能性。