大數據是什麼?從零開始,認識大數據定義、分析與工具 2026 年版
大數據是指規模龐大、難以用傳統方式儲存與處理的資料集合,核心特性以4V定義:Volume(資料量大,每日可產生一TB以上)、Variety(資料多樣,涵蓋文字、圖片、影片等形式)、Velocity(生成速度極快,人人隨時隨地產生資料)、Veracity(確保資料真實性,過濾異常值)。2026年大數據迎來三大趨勢:一是AI就緒架構成為企業核心設計目標,代理式AI(Agentic AI)可自主規劃並完成整套分析工作流程,語意層讓業務人員以自然語言直接查詢資料;二是數據湖屋(Data Lakehouse)全面取代傳統雙軌架構,串流優先設計實現秒級資料閉環,支援即時詐欺偵測、動態定價與物聯網設備監控;三是多模態AI協助整合非結構化資料,佔企業資料八至九成的電子郵件、客服錄音與合約文件終於釋放龐大洞察價值。大數據工具從Hadoop、Spark演進至Apache Iceberg等開放格式,企業正從靜態報表全面轉向對話式即時分析,大數據已成為每位決策者手中的智慧引擎。

電商巨頭亞馬遜透過「大數據」預測顧客行為,大幅減省物流與倉儲成本;阿里巴巴仰賴數據分析,打造品牌數據銀行並在11天內增加300萬位目標消費者;就連中華郵政也設定2019年為「數位元年」,開放郵務資料並舉辦競賽,計畫從大數據中找到提高作業效率、優化顧客體驗的方法。所謂「大數據」是指數量龐大而無法以傳統方式處理的資料,無論何種產業皆能透過分析大數據預測未來趨勢,使大數據成為各行業都在發展的數位技術。
大數據的興起使資料探勘、統計領域成為熱門科目,也使大數據工具開發更加快速、更容易取得與使用。以下會介紹大數據的定義、分析過程與相關工具,以及其背後的隱私爭議。即使你不曾聽過大數據,也能從無到有,了解大數據在數位時代備受關注的原因。
大數據的定義:4V
比起大數據,「數據」人人都熟悉,比如銀行戶頭的轉帳紀錄、網頁的瀏覽紀錄、購物網站中的消費紀錄,種種資料都可被稱為數據,而大數據就是這些資料的增量版。大數據還有以下幾種特性,統稱為4V:
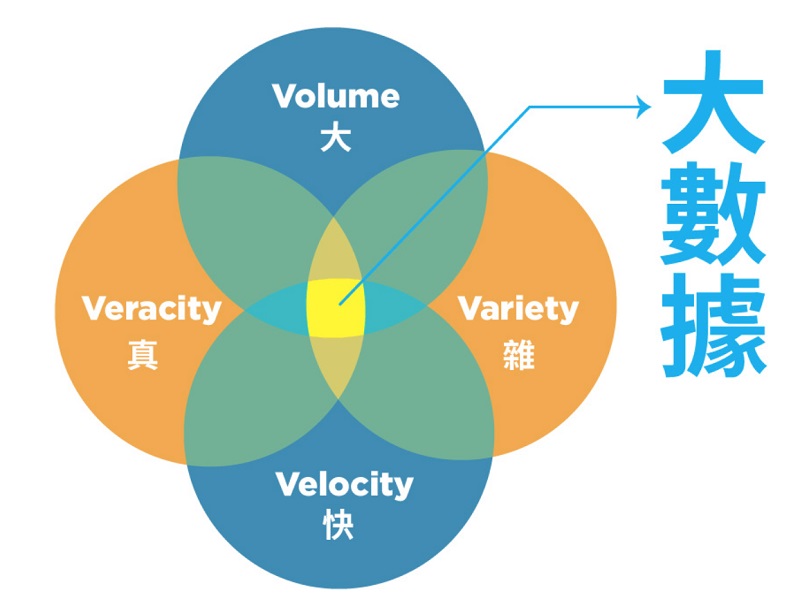
Volume大,資料量
大數據與傳統數據最大的差異在於資料量,資料量遠大於傳統數據,因此以「大數據」一詞來敘述並區分兩者的不同。若以量化表示,大數據特指在一天內可生成1TB以上資料量的數據,等同於128個8G隨身碟。也因為資料量大,無法以傳統的方式儲存處理,因此衍生出大數據這一新興科學。
Variety雜,資料多樣性
與前述的轉帳紀錄、瀏覽紀錄僅紀錄一種數據不同,大數據的資料類型龐雜,比如臉書上的帳戶紀錄,就包含照片、文字、超連結等多種數據形式。由於形式多元複雜,大數據儲存也需要不同於傳統數據的儲存技術。
Velocity快,資料即時性
大數據與傳統數據最大的不同點,就是生成速度飛快。由於網際網路興起與資訊設備普及,以用戶突破20億人的臉書為例,如果每個用戶每天按一個like,就會有20億筆資料。每一個人隨時隨地都可以創造數據,數據生成的速度已非過去可比擬。
Veracity真,資料真實性
在3V成為大數據的主要定義後,隨著儲存資料的成本下降、取得成本也下降,大數據發展出第四個特性:Veracity,意旨除了資料量,也需要確認資料的真實性,過濾掉造假的數據與異常值後,分析出來的結果才能達到準確預測的目的。
大數據分析:數據統計與資料探勘
比起大數據本身的4V特性,使它在數位時代脫穎而出的是準確預測未來的能力。而分析大數據的步驟其實與處理傳統數據相同,只是使用的工具有所差異。
數據統計是什麼?
處理數據的第一步是獲得並儲存,大數據在發展期間碰到的第一個問題就是資料生成過於快速且大量,需要開發新的儲存方式處理源源不絕的資料。
若能成功儲存大量資料,僅只是簡單的描述統計,也有助於了解提供數據者的特徵。職業數據網站Comparably就從數據面分析Google、臉書、微軟、蘋果、亞馬遜五家科技公司的面試難度,發現大多數Google的員工覺得面試過程很困難,反之到微軟面試工程職位時,即使穿著T恤、牛仔褲也可以被接受。從大量數據中即可發現各家公司的差異,應徵者也可以在面試前就做好相對應的心理準備。
資料探勘是什麼?
大數據無法使用過去人工方式統計與分析,即使能達成也需要耗費大量時間。因此在處理大數據時經常使用人工智慧、機器學習等技術,讓機器協助人類在短時間內分析巨量資料,這整理資料並找出其中規律的過程被稱為資料探勘。
資料探勘技術可以追蹤分析看似不相關的數據,應用在偵查、取得線索等領域上,甚至是追查犯罪者、預測犯罪地點。矽谷的大數據公司Palantir就以獨特的資料探勘技術,協助美國軍方找到蓋達組織首領賓拉登,也多次為企業與警方提供金融犯罪的線索。
大數據的分析步驟
大數據分析第一步:取得
數據隨時隨地都在產生,就連你上班時的行走路線,都可以成為商家選擇新店地址的參考資料。若是擁有大量使用者的企業,蒐集使用者的活動紀錄就可達到以數據預測未來的目標;若是較小型的企業,則可主動邀請使用者填寫問卷,逐步累積資訊量。
大數據分析第二步:儲存
由於資料量龐大,突破儲存技術式處理大數據的第一個難關。因此處理大數據時多使用分散式處理系統,透過分割資料與備份儲存,突破記憶體過小的障礙。
大數據分析第三步:運算
為達成預測未來的目的,機器可以透過分類、迴歸分析、排序、關聯分析等方式找出其中規律,並運用決策樹、遺傳演算法、人工神經網路等模型進行計算。
大數據分析第四步:視覺化
經過分析後的數據仍是數字與列表,不易閱讀。因此可搭配視覺化工具,將數據轉化為較容易閱讀與理解的形式。
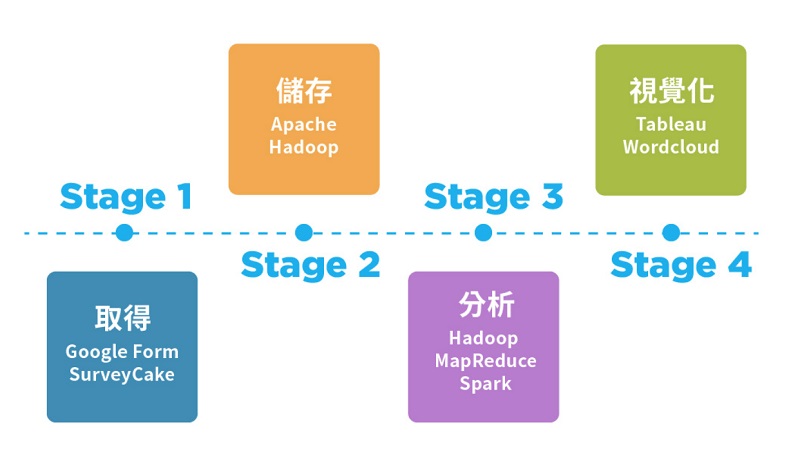
常見的大數據工具有哪些?
大數據取得工具:Google Form與SurveyCake
除了Amazom、Facebook等擁有大量使用者而能快速累積資料的大企業,一般企業可以用統計軟體取得資料,或請目標客群填寫問卷,持續累積資料量。相關工具包括:Google Form、SurveyCake,可以讓使用者免費製作線上問卷並提供簡單的問卷結果統計與分析。
大數據儲存工具:Apache Hadoop
目前最常見的大數據轉體技術為Hadoop,是由Apache軟體基金會使用Java語言所發展的軟體框架,並開放原始碼供人免費使用。
Hadoop使用HDFS分散式檔案系統(Hadoop Distributed File System),在儲存資料時,會將同一份檔案切割成小份,將每一小份製作多個備份後分別儲存在不同位置。即使部分資料損毀,也可使用其他備份重製出完整的資料。這種儲存技術可以突破巨量資料難以儲存的困境,同時確保資料的完整性,因此能成功累積資料並持續發展。
大數據分析工具:Hadoop MapReduce
Hadoop MapReduce是Hadoop的項目之一,可將儲存在HDFS中的資料調出、統計、處理後再回傳數據。整個Hadoop系統使用HDFS儲存資料,並交由Hadoop MapReduce處理資料,Hadoop MapReduce因此成為最常見的大數據分析軟體之一。
大數據分析工具:Spark
Spark是近年新型的大數據分析軟體,運算速度比Hadoop MapReduce還要快100倍。由於Hadoop MapReduce會在運算的同時儲存資料,資料需在記憶體與處理器之間不斷轉化。而Spark使用記憶體內運算技術,可直接在記憶體內運算,因此省下資料轉換時的能源與時間。
不過Spark只能分析大數據,而不能儲存大數據,使用時仍須搭配HDFS儲存系統,是Hadoop難以被取代的主要原因。
大數據視覺化工具:Tableau
Tableau可將大數據轉換為圖表、地圖等視覺化資料,並可以配合多種資料形式,包括Excel、txt、xml等,即使沒有科技背景的使用者也很容易操作,僅需平移、拖放等操作,適合用來呈現已分析過的資料。
大數據視覺化工具:Wordcloud
Wordcloud,又成為文字雲,可用來表示單一字詞在文件中出現的次數多寡與比例,且呈現方式簡單易懂,是非常常見的大數據視覺化方式,目前網路上也可找到處理少量資料的文字雲製作工具。

大數據的憂患:隱私
儘管大數據由於應用範圍廣泛,已成為各領域的發展趨勢,但數據的公布有時會伴隨使用者隱私的曝光,比如Facebook資料外洩、Google+個資外洩風波等因數據外洩而引發隱私問題的事件層出不窮。數據外洩問題會對蒐集數據的企業產生極大影響,動搖使用者的信心,甚至可能導致使用者不願再次使用產品。
企業在蒐集數據前應告知使用者將提供何種數據給第三方,以及數據可能的使用方式,並應維護使用者的隱私權。但當所有人隨時隨地都在產生數據、當數據對人的生活影響漸增, 隱私與正當使用的界線也值得探討,隱私也將成為未來大數據發展的方向。
大數據與人工智慧(AI)的共生關係
隨著大數據與人工智慧(AI)技術的快速發展,兩者之間形成了緊密的共生關係,相輔相成地推動各行各業的數位轉型。了解兩者之間的關係對於掌握現代科技發展趨勢至關重要。
AI 依賴大數據來訓練與優化模型
現代的AI(尤其是機器學習和深度學習模型)高度依賴大量的資料來進行訓練。資料愈多樣、愈龐大,模型就能學到更全面的模式,預測也更精確。例如,熱門的大型語言模型如ChatGPT就是利用數以百萬計的文件語料進行訓練,透過海量數據學習語言模式。沒有大數據作為「燃料」,AI演算法往往無法充分學習複雜的關係,智能程度也會大打折扣。
大數據促進AI更準確地預測與決策
大數據的蓬勃發展為AI提供了前所未有的資料來源,使AI模型能在更廣闊的情境中學習並驗證其算法。在大數據時代,企業和研究者可以取得長期累積的巨量資料來訓練AI,讓AI具備從過去經驗中預測未來的能力。充足且多元的數據讓AI的決策更有依據:模型不僅看到量的增長,也看到樣本多樣性,因此能捕捉到過去難以察覺的細微模式。換言之,巨量資料集讓高效的AI成為可能,提供了更全面的訓練,使其預測與決策能力大幅提升。
AI自動分析與處理大數據,提高數據價值
面對規模龐大且複雜的數據,傳統的人工分析已經力不從心,此時AI大顯身手。AI擅長高速處理和關聯分析,能從海量數據中自動識別出隱藏的模式與知識。這種能力可以將原本沉睡的大數據轉化為即時且可行的資訊價值。例如,社群媒體平台運用機器學習模型即時分析上億用戶的行為數據,據此動態調整每個人的訊息流內容和推薦頁面;串流影音服務商(如Netflix)利用大量觀眾的觀影記錄,由AI演算法預測每位觀眾可能喜愛的影片類型並加以推薦。由此可見,大數據與AI實質上形成了一種共生關係:一方面,大數據為AI提供了學習養分;另一方面,AI為大數據的分析利用提供了強大的工具。
大數據與AI的主要差異
儘管AI和大數據緊密相關,但在技術本質、應用場景和目標上仍存在顯著差異:
技術本質不同
人工智慧屬於演算法與軟體技術範疇,核心在於開發能模仿人類智能行為的模型和程式;而大數據則屬於資料處理與管理技術範疇,重點在於運用新的架構和工具來儲存、處理巨量且多元的資料。換言之,AI更關注「如何讓機器變聰明」,大數據則關注「如何處理極大量的資料」。兩者一個偏向算法與智能(例如神經網路、決策樹等AI模型),一個側重基礎設施與數據處理(例如Hadoop分散式儲存、Spark平行計算等框架)。
應用場景不同
AI通常應用在需要自動化決策或智慧化處理的場景,例如影像辨識、語音助理、自動駕駛等。這些應用都涉及讓機器「像人一樣」做出判斷或行動。
而大數據的典型應用場景是資料分析與統計,例如商業智能(分析消費者行為和市場趨勢)、科學研究中的資料探勘,或物聯網中感測器資料的即時監控。大數據應用往往著重於從數據中找出規律而非直接執行動作。
目標與作用不同
AI的最終目標是實現機器智慧,讓電腦系統能自主執行複雜任務並模擬人類的推理和決策過程。它追求的是行為上的智慧化,希望機器能「做出正確的行動」。
相較之下,大數據的目標在於從龐雜的資料中萃取知識,強調洞見的發現。簡而言之,AI注重決策和行動,讓機器成為決策主體;大數據注重分析和發現,為決策提供依據。
彼此依存與獨立性
從理論上說,AI和大數據可以被視為獨立的領域——我們可以有不依賴大數據的AI(例如基於知識規則的專家系統),也可以有不涉及AI的大數據分析(例如簡單的批次資料統計)。
然而在實踐中,兩者高度互補,往往相輔相成。在當代的技術圖景中,AI與大數據更多表現為一種互相依存的關係:大數據是AI的「原料」,機器學習是處理原料的方法,AI則是最終產出的智能成果。
2026 年大數據新趨勢:AI 融合、即時串流與數據湖屋
進入 2026 年,大數據領域正經歷一場深刻的典範轉移。大數據不再只是儲存與分析龐大資料的技術框架,而是與人工智慧、即時串流處理深度融合,成為企業數位競爭力的核心基礎設施。以下整理三個最值得關注的 2026 年大數據新趨勢。
AI 就緒架構:大數據從儲存轉向即時賦能
2026 年最重要的架構轉變,是企業將「AI 就緒」(AI Readiness)列為資料平台的核心設計目標。過去,大數據平台的優先任務是儲存與批次處理;如今,企業必須確保資料在產生的同時即完成治理、標準化與即時供給,因為 AI 模型若無法取得乾淨、即時的資料,預測與推論品質將大幅下降。這一趨勢催生了「語意層」(Semantic Layer)的普及——語意層為不同分析工具與 AI 系統提供共同的業務語言,讓資料從技術術語轉化為業務人員可直接運用的知識。
此外,以 ChatGPT 為代表的大型語言模型(LLM)持續演進為能自主規劃、執行與驗證分析流程的「代理式 AI」(Agentic AI)。這類系統無需逐步人工指引,即可自動檢查資料結構、識別品質問題並產出洞察報告,大幅縮短從資料到決策的時間。
串流優先的數據湖屋:批次處理走入歷史
2026 年,「數據湖屋」(Data Lakehouse)架構正式成為企業資料平台的主流選擇,取代過去分離的資料湖(Data Lake)與資料倉儲(Data Warehouse)雙軌架構。數據湖屋結合了資料湖的彈性儲存與資料倉儲的結構化查詢能力,並在 Apache Iceberg、Delta Lake 等開放表格格式的支持下,實現跨引擎的高度互通性。
更關鍵的是,2026 年的數據湖屋已從「批次優先」進化為「串流優先」(Streaming-First):資料的攝取、處理與查詢以連續串流方式進行,而非傳統的定時批次作業。Kafka 級別的事件驅動架構讓企業得以實現即時詐欺偵測、動態定價、物聯網設備監控與超個人化推薦,真正達成「從資料產生到洞察產出」的秒級閉環。
企業如何在 2026 年不同以往地運用大數據
相較於過去以「資料收集與報表製作」為主的大數據應用模式,2026 年的企業更強調以下三項轉變:其一,從靜態儀表板轉向對話式分析——業務主管可透過自然語言直接向資料系統提問,獲得即時答案;其二,合成資料(Synthetic Data)的大量應用——在資料隱私法規(如 GDPR)日趨嚴格的環境下,企業以統計準確的人工合成資料訓練 AI 模型,兼顧效率與合規;其三,非結構化資料的全面整合——估計佔企業資料總量 80% 至 90% 的非結構化資料(如電子郵件、客服錄音、合約文件),在多模態 AI 的協助下終於得以系統性分析,成為企業洞察的重要礦源。這三項轉變共同說明:大數據在 2026 年已不再是 IT 部門的專屬工具,而是每位決策者手中隨時可用的智慧引擎。
大數據快速掌握現在局勢、推斷未來走向
大數據由於基數龐大,從中推斷出的趨勢因此足夠準確。除了電商可用大數據完成預測式購物、社群網站可以推薦使用者感興趣的內容,一般企業也可以大數據監控網路輿情,了解目前消費者的喜好,做出精準行銷決策與準確公關反應。
InfoMiner 即時輿情分析平台使用自行研發的大數據、人工智慧處理技術與文字探勘技術,可以即時掌握社群風向,追蹤特定關鍵字,彙整為短文與圖表,分析輿情,以Email或LINE將目前最新的即時輿論資訊寄送給使用者。掌握最新情報,在危機發生時第一時間反應,作好危機處理降低風險。
延伸閱讀:一次了解大數據應用:商業決策前的必修課